
浅析Java一些新特性
project amber 琥珀计划
project amber 是为了改善 Java 复杂语法而创建的,目的是提高 Java 代码简洁性。Var 关键字
该特性在 JDK10 正式引入和 js 中的 var 一样,用于定义一个变量而不需要指定这个变量的类型,由编译器在编译时推断。
1 | // 传统方式 |
简化多行文本String表达式
该特性在 JDK15 正式引入将包含多个换行符的 String 用更自然的方式呈现
1 | // 传统方式 |
switch 表达式简化
该特性在 JDK14 正式引入1 | // 传统 switch 语句 |
yield 几乎是为了 switch 表达式存在的。
switch 从传统的语句演变为表达式后,当 case 或 default 分支需要执行复杂逻辑,而不只是简单的返回一个值时,就需要使用代码块 {} 来包裹这些逻辑。但代码块不能自动将其中的某个值作为返回值给 switch 表达式,这时就需要 yield 关键字来显式指定返回值。
record 类
该特性在 JDK16 正式引入(JDK16 中一同引入的还有用于科学计算的 Vector API,但仍处于孵化阶段。见Record 类是一种特殊的类,用于创建所有字段都被 final 修饰的类。它可以自动生成构造方法、toString()、equals() 和 hashCode() 等方法,减少了样板代码。类似于 lombok,但不如 lombok 功能丰富。
1 | // 传统方式定义不可变类 |
密封类和接口
该特性在 JDK16 正式引入。使用 sealed 关键字修饰类或接口,并使用 permits 子句指定特定的类实现它。
不太明白这个特性有什么用。
1 | // 定义完这个接口后,意味着只有Circle或者Rectangle类及其子类可以实现这个接口 |
instanceof 模式匹配
该特性在 JDK16 正式引入。在 instanceof 表达式内可以隐式赋值。
1 | // 传统方式 |
虚拟线程
该特性在 JDK21 正式引入。是一种轻量级线程,它在很多其他语言中被称为协程、纤程、绿色线程、用户态线程等。
介绍虚拟线程之前,先回顾一下 Java 线程面临的问题:
- 线程状态切换开销大。 Java 线程根据 1 对多,1 对 1 等关系直接映射操作系统线程。Java 线程的创建、调度、销毁都需要操作系统介入,开销较大。多线程执行任务时性能提升还不够。
- 线程占据栈空间较大。每个线程要占据一定的栈空间。
- 阻塞处理方式不好。遇到 IO 操作时,对应的 Java 线程会进入阻塞态(如果一个操作系统线程对应多个 Java 线程,这也是虚拟线程的模型。操作系统线程也会进入阻塞态吗?)。
再来看看什么是虚拟线程:
虚拟线程定义:
虚拟线程是一种逻辑上的线程,它并不直接对应于操作系统的物理线程。相反,虚拟线程是由JVM在内部管理的,它通过在物理线程上执行来模拟多线程的行为。
虚拟线程可以看作是轻量级的线程,由Java虚拟机自己管理和调度,而不需要操作系统的干预。虚拟线程可以在一个物理线程上执行多个虚拟线程,并通过合理的调度算法实现并发执行。
总结:一个 Java 线程对应的多个虚拟线程可以理解为单线程执行的多线程模型。当一个虚拟线程遇到 IO 操作时,该虚拟线程进入阻塞态。,但底下那个 Java 线程不受影响还是运行态(咋实现的呢?)。
回顾上面列举的 Java 线程缺陷,看看虚拟线程是怎么改善的:
- 线程状态切换开销大。虚拟线程的创建和销毁由 JVM 在用户态完成,无需操作系统内核的介入,开销极小。JVM 会根据虚拟线程的状态和优先级进行高效调度。
- 线程占据栈空间较大。虚拟线程的栈内存是动态分配的,且占用的内存非常小,通常只有几十 KB。
- 虚拟线程在遇到IO阻塞操作时,会让出执行权,让其他虚拟线程继续执行。JVM 运行时会将 Java 线程分配给其他可运行的虚拟线程,从而避免了线程资源的浪费。当阻塞操作完成后,由于像 epoll 这样的事件回调机制的 IO 模型,该虚拟线程会被唤醒进入就绪态,再根据一些调度算法如多级反馈调度,进入执行态(是的,虚拟线程也有我们熟知的多种线程状态)。
因此使用虚拟线程提升性能最大的系统类型是IO密集型。由于多个虚拟线程对应的同一个Java线程,对CPU密集型系统性能无提升。
java线程和操作系统线程是直接对应的,大量创建Java线程不仅会导致操作系统频繁分配栈内存,更有操作系统参与的大量线程上下文切换开销,对CPU造成较大的压力。
而虚拟线程和操作系统没啥关系,且它的栈信息保存在堆内存中,大量创建虚拟线程导致的是GC压力。
关于虚拟线程与GC的关系可参考此文
逻辑上代码是由虚拟线程执行,但实际上还是 Java 线程在执行。类似于只有一个核心的 CPU,运行着多线程。CPU(Java 线程)一直在 work,但是线程(虚拟线程)不会一直 work,而是在运行态、就绪态、阻塞态之间切换,甚至是终结态消灭这个线程。
了解更多关于虚拟线程的信息,参阅JDK21有没有什么稳定、简单又强势的特性?
native image
注: native image 是 Java AOT 编译的一种方案
很多人说 Java 程序很臃肿,吃内存。
我现写一个只有 hello world 功能的 spring 项目,整个项目就两个类。

运行看看内存占用:

确实占了不少内存。
接着修改 pom.xml,改为 native image 编译。
完整的 native image 编译模式的 pom.xml 内容见文章末尾。
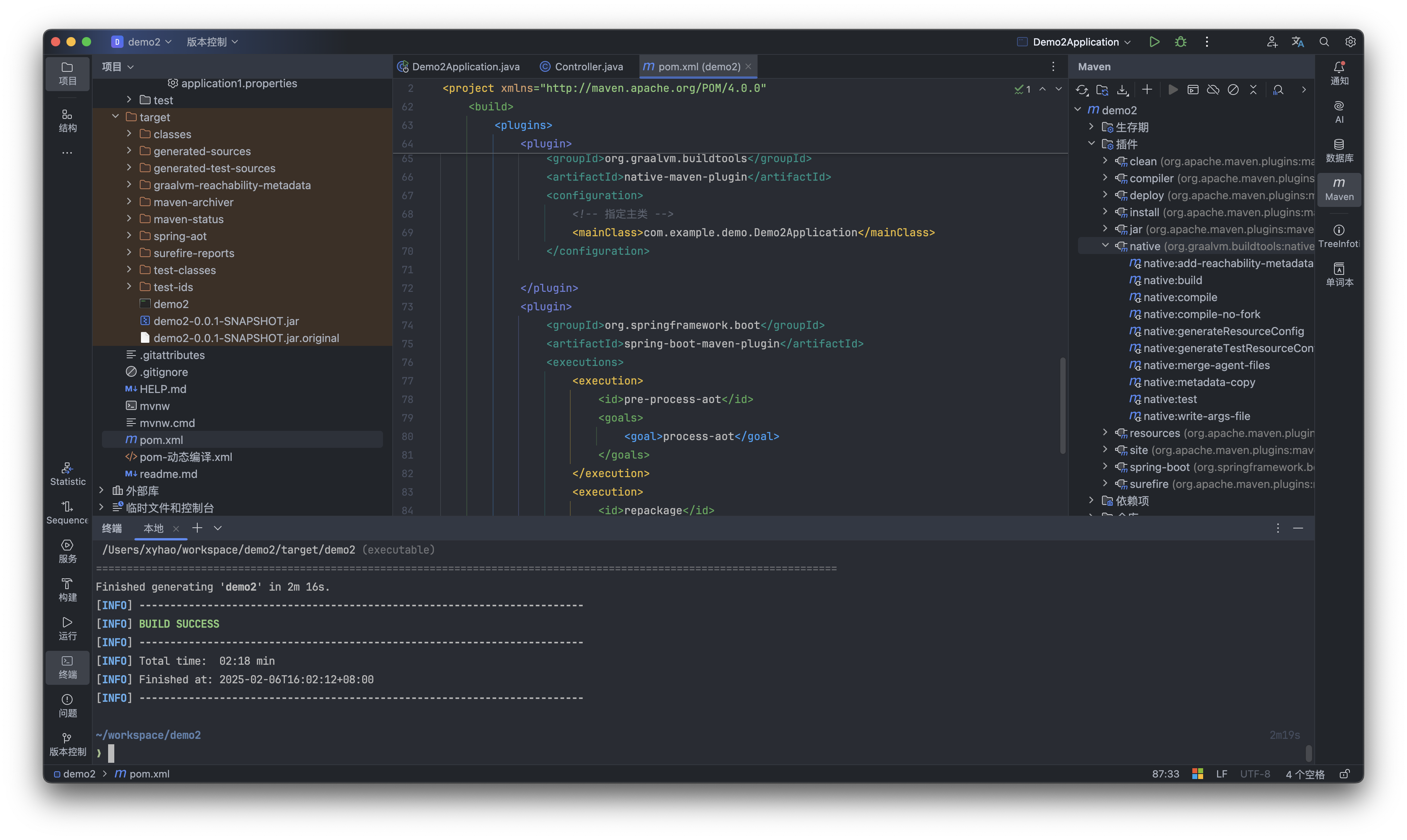
终端执行 mvn native:compile-no-fork。如上图,编译了02:18min 后,在 target目录下出现了一个 unix 可执行文件 demo2[1]
静态编译真的很慢,更何况这只是个包含两个类的helloWorld程序。
运行它:


内存占用 由 166.2MB 降低到了 48.49MB
有了 native image,怎么好意思说 java 很臃肿、启动很慢?
但是代价就是没有了 JVM:
- Java 程序的许多动态特性都不直接生效了,例如动态类加载,反射,动态代理等。需要使用 GraalVM 提供的额外配置方式来解决这个问题。
- 丧失了 Java 程序多年来引以为傲的平台无关性。
- 最重要的是,基于字节码改写实现的 Java Agent 将不再适用,因为没有了字节码概念,所以之前我们通过 Java Agent 做到的各种可观测能力,例如收集 Trace/Metrics 等信号这些能力都不能生效了。
像 Java Agent 的代表之一 :arthas ,就无法使用在编译后的 unix 可执行文件上。
arthas 的原理是基于 JVM 实现了插桩、动态代理、和Instrumentation接口 (skywalking也是通过这个接口实现了修改后字节码的加载)。
可以试试 arthas 能不能跟踪到 demo2 程序:

很明显不能
改为原来的 jit 编译,arthas 生效

那么如何在 native image 模式下使 Java-Agent 生效呢?
阿里那边有一些工作可供参考:
GraalVM 静态编译下 OTel Java Agent 的自动增强方案与实现
但是目前来看,native image并不比JIT更优秀。graalVM毕竟还是比较新的技术,一旦出现什么问题或者编译错误,在google上找不到解决方案就难受了。
而且单论性能,预热后的JIT也不输native image。graalVM 的 native image为了提前编译做出了很多取舍,比如G1收集器在以前收费的企业版里才支持,而且吞吐量下降明显。
目前来看 graalVM 的 native image最大的优点就是启动快,初始内存占用低。适合Java语言开发的客户端应用,但不适合服务器上长期运行的程序。
Java这门语言还有很长的路要走。
概念普及:
动态编译 JIT:
代码经过编译后得到字节码。
如Java代码编译得到字节码,字节码由 JVM 逐行解释,翻译为机器码给 CPU 执行。对于执行频繁的热点字节码,经过 JIT 编译成机器码让 CPU 直接执行。这印证了Java是半编译半解释的语言。解释器的优点是:启动速度快,对于那些只执行少量次数的代码,使用解释器执行可以避免 JIT 编译带来的额外开销。例如,一些只在特定条件下才会执行的代码块,或者在程序启动阶段执行一次的初始化代码,使用解释器执行更为合适。
静态编译:
将 C++,C 等代码编译为操作系统相关的二进制文件,如 Mac 上的 unix 可执行文件,Windows 的 exe,Linux 上的 deb。
AOT 编译
静态编译的一种。 AOT 是将 Java 代码编译后得到的字节码再编译为机器码,得到操作系统相关的二进制文件。上文中反复提到的 native image 就是 AOT 编译的一种。
这使得运行 Java 程序就像打开 app 一样简单。并且内存占用相较于执行 jar 包而言变得很低。但是 Java 引以为傲的平台无关性消失了。
由于字节码没有被跳过,Java 程序的动态代理、反射等特性还是可以使用的。
可以理解为 AOT 是静态编译在 Java 的具体实现。
静态编译和动态编译的最大区别就是生成机器码的时机。
程序未运行就已经生成了机器码叫静态编译。
程序运行时才根据执行情况将一部分代码编译为机器码,叫动态编译。
ZGC & shanendoahGC
待续叶公好龙
叶公喜欢龙是出了名的,所有人都知道,然后有一天,龙真的来了,叶公躲到床下,浑身哆嗦吓得半死标榜自己爱好技术的人很多,但真正想要解决问题的人很少
经常看到技术人员各种抱怨,以java为例,无数的人在说java语法繁琐,gc pause,启动慢,ui丑,等等
不可否认,他们说的都是事实,但问题是,他们只看到了问题,却不去想着怎么解决问题
不想着解决也无可厚非,又不是从事编译器开发工作或者 jdk 开发者。
但有意思的是,当你告诉他们,java语法繁琐有project amber在解决,gc有zgc,shanendoah在解决,启动慢有aot,大有native image,当你把这些解决方案罗列到他们面前的时候
很多人的表现居然是抗拒,而不是尝试
因为他们突然发现,有新的东西要学了
这难道不是他们一直以来备受困扰的问题吗?当别人把免费的解决方案放到他手上的时候
居然不敢用?不敢试?活脱脱的现实版叶公
附录:pom.xml
1 |
|









